
I was speaking with recently on the topic of MDM -
it occurred to me not too long after we began the conversation that we more
than likely had differing perspectives as to what Master Data Management meant.
That's inspired me to write this post to talk a little bit about how better to understand MDM.
MDM, The Core Concept:
Let's start with what Master Data is not, Master data is not:
MDM, The Core Concept:
Let's start with what Master Data is not, Master data is not:
- Meta-data, which is a description of data (or data about data as it's commonly referred to as).
- Ontology, Taxonomy or Vocabulary - Master data can be derived from these but is not in itself a formal semantic construct.
- Software Tool - ultimately, Master Data is technology-agnostic; it is a logical construct which can be defined through various modeling tools and realized through a variety of data management software solutions. At the point where Master Data becomes tightly coupled with any one software tool or any one modeling technique it will likely loose a great deal of its potential value to the enterprise.
So, then what is it? How would we characterize what can
become Master Data or not ?
- It may be considered "data of record" or an authoritative data source, but it might not be also. Data of record implies that there is a system of record with sanctioned data elements that are not meant to be repeated throughout the enterprise across other systems. Or this might refer to data entities which are determined to be unique and authoritative across the enterprise regardless of their current use (in a system).
- Master data is reference data, sort of. If we consider that reference data is a definitive set of element definitions or entities associated with any particular business domain, sub-domain or problem space. In this capacity, Master Data may serve multiple roles, including: discovery, registry or repository access, data dictionary foundation.
- Benchmark - this is a critical consideration; any data entities defined as Master Data elements within an enterprise are unlikely to remain unchanged or unmodified. Eventually there will be variations of Master Data sets, these variations must be tracked back to their source and there must also be a mechanism whereby others in the enterprise can understand where, why and how those modifications occurred 'atop' the core sets of Master Data. Thus the Master Data is a baseline or benchmark wherein the data chain of custody can be managed or tracked.
- It can be a canonical data model or data exchange model - this is important in cases where the core data architecture has not yet been designed or deployed, or in cases where it is anticipated that there will be a major or radical transformation of the existing architecture to a new one. The model can contain Master Data elements or sets within it.
MDM in Today's Implementations
Much of what we refer to now as MDM solutions have been borne out of previous product solutions that were describe as meta-data management solutions. For many of the MDM solutions on the market, the "repository or registry" architectural construct / pattern is how this capability is harnessed. Another architectural approach related to MDM might be referred to as the middleware design - this extends MDM into data transport and is focused on supporting accurate message translation. And of course there are solutions that combine both aspects.
Much of what we refer to now as MDM solutions have been borne out of previous product solutions that were describe as meta-data management solutions. For many of the MDM solutions on the market, the "repository or registry" architectural construct / pattern is how this capability is harnessed. Another architectural approach related to MDM might be referred to as the middleware design - this extends MDM into data transport and is focused on supporting accurate message translation. And of course there are solutions that combine both aspects.
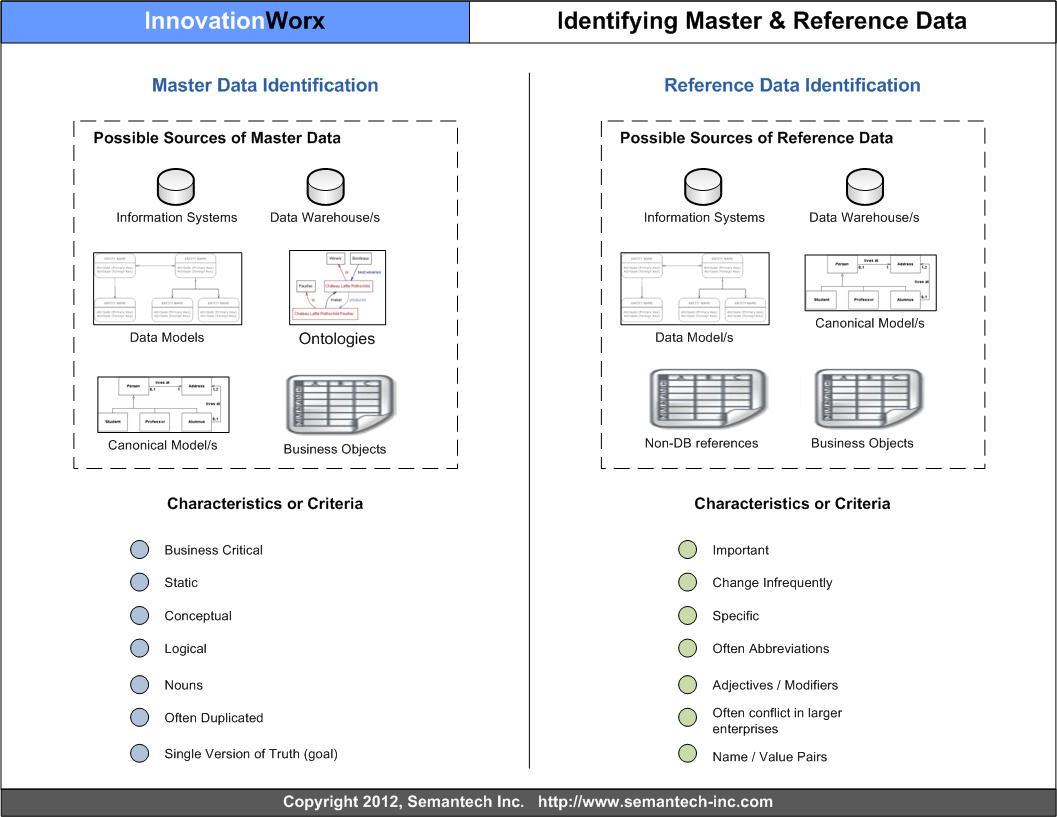 |
| One of the most important aspects of MDM is identifying what constitutes Master and Reference Data |
Perhaps we can consider that there are at least two philosophical approaches to
MDM:
- Passive MDM - This is most closely aligned to the original Meta-data management solutions with a central repository to support discovery and high level data reconciliation.
- Active MDM - This is most closely aligned with solutions stemming from EAI, Middleware, ETL based solutions where data reconciliation rules are being applied at multiple levels and in more detail.
- Hybrid MDM - Both solutions are relatively weak in dealing with bi-directional reconciliation focused heavily on transactional systems (it is much easier to reconcile historical data from multiple sources than real-time data from multiple sources). Hybrid MDM applies both previous techniques and new ones to tackle the most problematic use cases.
As we've discovered with nearly every IT technology and product over the past 40 years - implementation without process or architectural considerations leads to many issues, often more issues than existed before the technology was introduced. This is no exception with MDM - the most important thing to consider here is that deployment of MDM software can significantly impact or influence both solution performance and integrity but proceeding without working through the implicit architectural / enterprise issues is risky.
Copyright 2012 - Technovation Talks, Semantech Inc.











0 comments:
Post a Comment